Artefact eBook Reader / 1 ЙАОС 2004 З.
оХ-ОХ, ОЕ ОХЦОП УНЕСФШУС. оБЪЧБОЙЕ ЛБЛ ОБЪЧБОЙЕ. оХЦОП ЦЕ ВЩМП ЛБЛ-ФП ОБЪЧБФШ. юЙФБМЛБ ЬМЕЛФТПООЩИ ЛОЙЗ УП ЧУФТПЕООЩН БОЗМП-ТХУУЛЙН УМПЧБТЈН. уМПЧБТШ ЧУЈ ЧТЕНС УЙДЙФ Ч ОЕВПМШЫПН ЖТЕКНЕ УРТБЧБ à la Lingvo, ЛХЫБФШ ОЕ РТПУЙФ, ТБВПФБЕФ РТЙ ДЧПКОПН ЭЕМЮЛЕ ОБ УМПЧЕ ЙМЙ ЧЩДЕМЕОЙС УМПЧБ ЙМЙ ЕЗП ЖТБЗНЕОФБ НЩЫЛПК.
оЕ ЪОБА, РТЙЗПДЙФУС МЙ ЬФП ЕЭЈ ЛПНХ-ОЙВХДШ, ОП РБТЕ ЪОБЛПНЩИ УЙМШОП РТЙЗПДЙМПУШ. уЛБЮБМП ЬФП РТПЙЪЧЕДЕОЙЕ ЙУЛХУУФЧБ 4178 ЮЕМПЧЕЛ (ОБ ЛПОЕГ 2005 З.), ЪБ ДПР. ЙОУФТХЛГЙСНЙ ПВТБФЙМПУШ ЮЕМПЧЕЛ 30, ФПЮОП ОЕ РПНОА.
уЕКЮБУ ЧТПДЕ ЛБЛ ХЦЕ ЕУФШ НОПЗП ЗПТБЪДП ВПМЕЕ ЖХОЛГЙПОБМШОПЗП УПЖФБ, ОП ЧУЈ ТБЧОП ЧЩЛМБДЩЧБА ЧНЕУФЕ УП ЧУЕНЙ ЙОУФТХЛГЙСНЙ Й БЛУЕУУХБТБНЙ. оЕ ЧЩВТБУЩЧБФШ ЦЕ.
рТПФЕУФЙТХКФЕ УЙУФЕНХ ЪДЕУШ. рТЙ ПФЛТЩФЙЙ ЪБЗТХЪЙФУС ОЕЛБС ЛОЙЗБ, ЛПФПТХА НПЦОП РПРТПВПЧБФШ РПЮЙФБФШ. рЩФБФШУС ПФЛТЩФШ МПЛБМШОЩЕ ЖБКМЩ ОЕ УФПЙФ, ОЕ РПМХЮЙФУС.
оП ЧПФ УЛБЮБФШ Й ХУФБОПЧЙФШ ДМС ЛПТТЕЛФОПК ТБВПФЩ ТЙДЕТБ ОХЦОП ОЕНБМП. рТБЧДБ, ЧУЕЗП ПДЙО ТБЪ.
йОУФТХЛГЙЙ РП УВПТЛЕ
лБЮБЕН УМЕДХАЭЙЕ ЛПНРПОЕОФЩ:
Active Perl for Win32 (~9 нВ)
Apache Web Server (~7 нВ)
уМПЧБТШ Й УЛТЙРФЩ (2,2 нВ)
жБКМ ЛПОЖЙЗХТБГЙЙ Apache (10 лВ)
нБЛТПУ ДМС MS Word (1 лВ)
дБМЕЕ РП РПТСДЛХ:
1. йОУФБММЙТХЕН Active Perl Ч РТЕДМБЗБЕНЩК ЙОУФБММСФПТПН ЛБФБМПЗ.
2. фП ЦЕ УБНПЕ ДЕМБЕН У Apache. оБ ЧПРТПУЩ ПВ ЙНЕОЙ УЕТЧЕТБ ЧЧПДЙН Ч ПВБ РПМС «localhost».
3. тБЪБТИЙЧЙТХЕН УМПЧБТШ Й УЛТЙРФЩ Ч ЛБФБМПЗ C:\Program Files\Apache Group\Apache2\cgi-bin\.
4. ъБНЕОСЕН ЖБКМ ЛПОЖЙЗХТБГЙЙ, ОБИПДСЭЙКУС РП БДТЕУХ C:\Program Files\Apache Group\Apache2\conf\httpd.conf, ФЕН, ЛПФПТЩК УЛБЮБМЙ У ЬФПК УФТБОЙГЩ.
5. ъБРХУЛБЕН (РЕТЕЪБРХУЛБЕН) Apache.
6. оБВЙТБЕН Ч БДТЕУОПК УФТПЛЕ УФТПЛЕ ВТБХЪЕТБ http://localhost/cgi-bin/dindex.pl.
7. мАВХЕНУС ТЕЪХМШФБФПН.
лОЙЦЛЙ ЙЪ ВЙВМЙПФЕЛЙ «бТФЕЖБЛФ» РЕТЕЗПОСЕН Ч ЖПТНБФ, ДПУФХРОЩК ТЙДЕТХ, У РПНПЭША УЛБЮБООПЗП НБЛТПУБ:
1. пФЛТЩЧБЕН ВЙВМЙПФЕЮОЩК ЖБКМ Ч Word.
2. ъБРХУЛБЕН НБЛТПУ, РПМХЮБС HTML-ЛПД РТСНП Ч ДПЛХНЕОФЕ Word.
3. уПЪДБЈН ОБ ДЙУЛЕ РХУФПК .txt-ЖБКМ Й ПФЛТЩЧБЕН ЕЗП.
4. лПРЙТХЕН ФХДБ ФЕЛУФ ЧПТДПЧУЛПЗП ДПЛХНЕОФБ.
5. уПИТБОСЕН .txt-ЖБКМ Й РЕТЕЙНЕОПЧЩЧБЕН ЕЗП Ч .htm.
йНЕООП ФБЛ, Й ОЙЛБЛ ЙОБЮЕ, ЙОБЮЕ ХВШАФУС «РТБЧЙМШОЩЕ» ЛБЧЩЮЛЙ, ДБ Й ОЕ ФПМШЛП ПОЙ. дБ, РПМХЮЕООПНХ ЖБКМХ ОЕ ТЕЛПНЕОДХЕФУС ДБЧБФШ ТХУУЛПЕ ЙНС, ЙОБЮЕ ТЙДЕТ ЕЗП ОЕ ПФЛТПЕФ. ьФП МЕЗЛП ЙУРТБЧЙФШ, ОП РПЛБ... УБНЙ РПОЙНБЕФЕ.
фЕПТЕФЙЮЕУЛЙ ТЙДЕТ ХЦЕ УЕКЮБУ РПЪЧПМСЕФ ЮЙФБФШ МАВЩЕ .txt Й .htm/.html ЖБКМЩ (У РПРТБЧЛПК ОБ ТХУУЛЙЕ ЙНЕОБ). рТБЛФЙЮЕУЛЙ ЦЕ... ЛБЛ РПМХЮЙФУС.
рПНОЙФЕ: УЙУФЕНБ ТБВПФБЕФ фпмшлп У ЪБРХЭЕООЩН Apache.
йОУФТХЛГЙС РП ЙУРПМШЪПЧБОЙА
оБ ЪБЗТХЦЕООПК УФТБОЙГЕ ЧЩ ПВОБТХЦЙФЕ УЙУФЕНХ ЙЪ ДЧХИ ЖТЕКНПЧ. ч МЕЧЩК ЪБЗТХЦБЕФУС ЛОЙЗБ, Ч РТБЧЩК — ЙОФЕТЖЕКУ УМПЧБТС. юЙФБКФЕ ФЕЛУФ ЛОЙЗЙ. лБЛ ФПМШЛП ЧУФТЕФЙФУС ОЕЪОБЛПНПЕ УМПЧП, ЧЩДЕМЙФЕ ЕЗП НЩЫША Й (РПУМЕ ОЕЛПФПТПК ЪБДЕТЦЛЙ, УЧСЪБООПК УП УЛПТПУФША ЧБЫЕЗП УПЕДЙОЕОЙС У ЙОФЕТОЕФПН) РПДПЦДЙФЕ РПСЧМЕОЙС РЕТЕЧПДБ Ч РТБЧПН ЖТЕКНЕ. чЩДЕМСФШ ФЕЛУФ НПЦОП ЛБЛ ДЧПКОЩН ЭЕМЮЛПН ОБ УМПЧЕ, ФБЛ Й РЕТЕНЕЭЕОЙЕН ЛХТУПТБ НЩЫЙ РТЙ ОБЦБФПК МЕЧПК ЛОПРЛЕ: ЧЩДЕМЕОЙЕ ЮБУФЙ УМПЧБ ФБЛЦЕ УТБВПФБЕФ. рТБЧЩК ЖТЕКН ФБЛЦЕ НПЦОП ЙУРПМШЪПЧБФШ ЛБЛ ОЕЪБЧЙУЙНЩК УМПЧБТШ, ЧЩДЕМЕОЙС Ч ОЈН ФПЦЕ ТБВПФБАФ.
чЩЗМСДЙФ ЬФП РТЙНЕТОП ФБЛ (МЕЧЩК ЖТЕКН, ТБЪХНЕЕФУС, Ч ТЕБМШОПУФЙ ЗПТБЪДП ЫЙТЕ):
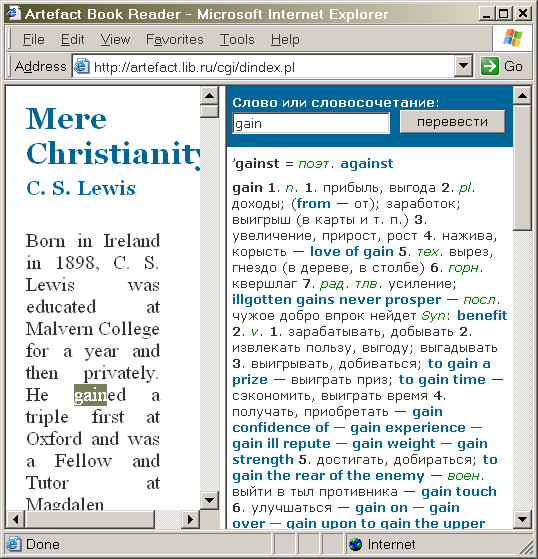
б ФЕРЕТШ РТЕДУФБЧШФЕ, ЮФП ЬФБ УЙУФЕНБ ТБВПФБЕФ Х ЧБУ ОБ ЛПНРШАФЕТЕ, Й ЪБДЕТЦЛБ НЕЦДХ ЧЩДЕМЕОЙЕН УМПЧБ Й РПСЧМЕОЙЕН РЕТЕЧПДБ ПФУХФУФЧХЕФ. чЕУЙФ ЧУЈ ЬФП ИПЪСКУФЧП ПЛПМП 7 НЕЗБВБКФ, Ч УМПЧБТЕ ПЛПМП 70 ФЩУСЮ УМПЧ, ОП НПЦЕФ ВЩФШ ЗПТБЪДП ВПМШЫЕ. йНЕАЭЙКУС НБЛТПУ ДМС MS Word ЪБ ОЕУЛПМШЛП УЕЛХОД РТЕПВТБЪХЕФ Ч ЖПТНБФ, РПОСФОЩК ТЙДЕТХ, МАВПК ЙЪ РТЕДУФБЧМЕООЩИ Ч ВЙВМЙПФЕЛЕ «бТФЕЖБЛФ» ФЕЛУФПЧ, ДБ Й ЧППВЭЕ МАВПК ЬМЕЛФТПООЩК ФЕЛУФ.
дБ, ЕЭЈ ЛПЕ-ЮФП: УЙУФЕНБ, Л УПЦБМЕОЙА, ТБВПФБЕФ ФПМШЛП Ч Internet Explorer. еУМЙ РПФТЕВХЕФУС, ОЕУМПЦОП ПВЕУРЕЮЙФШ УПЧНЕУФЙНПУФШ У ДТХЗЙНЙ ВТБХЪЕТБНЙ. дМС ОЕДПЧПМШОЩИ ТБЪНЕТПН ЫТЙЖФПЧ: ЧУРПНОЙФЕ П РХОЛФЕ НЕОА View | Text Size.
уМПЧБТШ УДЕМБО ОБ ПУОПЧЕ 24-ЗП ЙЪДБОЙС БОЗМП-ТХУУЛПЗП УМПЧБТС нАММЕТБ, ЧЪСФПЗП УП УФТБОЙГЩ бОЗМП-ТХУУЛЙК УМПЧБТШ нАММЕТБ ДМС Unix Й УЧПВПДОП ТБУРТПУФТБОСЕНПЗП Ч ЙОФЕТОЕФЕ. рПЛБ ПО ВЕЪ ФТБОУЛТЙРГЙЙ, ОП ЬФП ЙУРТБЧЙНП.
дПРПМОЕОЙЕ
зПУРПДБ, ЕУМЙ ЛФП-ФП ОЕ РПОСМ: УМПЧБТШ ОЕ Ч УПУФПСОЙЙ ОБКФЙ УМПЧБ У ЖМЕЛФЙЧОЩНЙ ПЛПОЮБОЙСНЙ. оП НПЦОП ЧЩДЕМЙФШ НЩЫША «part» Ч УМПЧЕ «parts» ЙМЙ «develop» Ч УМПЧЕ «development», Й УМПЧБТШ, РЕТЕИЧБФЩЧБАЭЙК МАВЩЕ ЧЩДЕМЕОЙС, ЧЩДБУФ ЧУЈ, ОБ ЮФП ПО УРПУПВЕО. ;-)
рМБОЩ РП ТБЪЧЙФЙА (Б ЧДТХЗ?..)
оХЦОЩ УМПЧБТЙ. бОЗМЙКУЛЙК, ОЕНЕГЛЙК, ЖТБОГХЪУЛЙК... ПФЛТЩФПЗП ЖПТНБФБ, УБНЙ РПОЙНБЕФЕ. вПМШЫЙЕ. оЕ ПВСЪБФЕМШОП У ТБЪНЕФЛПК: нАММЕТ ХДБМПУШ ОПТНБМШОП ТБУРБТУЙФШ Й ВЕЪ ОЕЈ. юЕН ВПМШЫЕ УМПЧБТЕК Х НЕОС ПЛБЦЕФУС, ФЕН ВПМШЫЕЕ ЛПМЙЮЕУФЧП СЪЩЛПЧ ВХДЕФ РПДДЕТЦЙЧБФШ ТЙДЕТ. оБ УЕЗПДОСЫОЙК ДЕОШ ЕУФШ бРТЕУСО У ФТБОУЛТЙРГЙЕК (127 000 УМПЧ), ОЕНЕГЛЙК дХДЕО (ФПМЛПЧЩК) Й чЕВУФЕТ. ьФПЗП, ТБЪХНЕЕФУС, НБМП.
ОБЧЕТИ
|