йОФЕТЕУОЩК РТЙНЕТ ЙУРПМШЪПЧБОЙС ЖХОЛГЙЙ Find & Replace / 8 НБС 2018 З.
рПУФБОПЧЛБ ЪБДБЮЙ
еУФШ ДПЛХНЕОФ Word У ФЕЛУФПН ЛОЙЗЙ, ЪБЗПМПЧЛЙ Ч ЛПФПТПН ПФПВТБЦБАФУС УМЕДХАЭЙН ПВТБЪПН:

оХЦОП:
1. рТЕПВТБЪПЧБФШ УФТПЛХ У ОПНЕТПН ЗМБЧЩ Ч Sentence case.
2. рТЕПВТБЪПЧБФШ УФТПЛХ У ОБЪЧБОЙЕН ЗМБЧЩ Ч UPPERCASE.
3. бЛФЙЧЙТПЧБФШ ПРГЙА Keep with next ДМС ЬФЙИ ДЧХИ БВЪБГЕЧ Й УМЕДХАЭЕЗП ЪБ ОЙНЙ, УПДЕТЦБЭЕЗП РХУФХА УФТПЛХ Й ПФВЙЧБАЭЕЗП ОБЪЧБОЙЕ ЗМБЧЩ ПФ ЕЈ РЕТЧПЗП БВЪБГБ.
4. пФЖПТНБФЙТПЧБФШ ЧУЕ ФТЙ ХРПНСОХФЩИ БВЪБГБ У ЧЩЛМАЮЛПК ЧМЕЧП.
рПРЩФЛБ ТЕЫЙФШ
уОБЮБМБ С РПРТПВПЧБМ РПРТПЗТБННЙТПЧБФШ (ИПФС, ЛБЛ ЧЩ ХУРЕМЙ ЪБНЕФЙФШ, РТПЗТБННЙУФ ЙЪ НЕОС, ЛБЛ ЙЪ ДЙЪЕОФЕТЙКОПК БНЈВЩ ЗТБОБФБ). оХЦОП ВЩМП:
1. рТПЗТБННОП ЙУЛБФШ РПДУФТПЛХ «CAPÍTULOћ» (ОБРПНОА, ЮФП ФПЮЛБ Ч УТЕДОЕК РПЪЙГЙЙ Ч ДБООПН УМХЮБЕ УППФЧЕФУФЧХЕФ ПВЩЮОПНХ РТПВЕМХ) Й РТПДЕМЩЧБФШ У УПДЕТЦБЭЙН ЕЈ БВЪБГЕН РПУМЕДПЧБФЕМШОП 1), 3) Й 4).
2 рЕТЕИПДЙФШ Л УМЕДХАЭЕНХ БВЪБГХ Й РТПДЕМЩЧБФШ У ОЙН 2), 3) Й 4).
3. рТЕИПДЙФШ Л УМЕДХАЭЕНХ БВЪБГХ, ДБМЕЕ 3) Й 4).
нПЕЗП ЪОБОЙС ПВЯЕЛФОПК НПДЕМЙ ДПЛХНЕОФБ Word ОБ ЧУЈ ЬФП ОЕ ИЧБФЙМП, Б ЛПЗДБ ЧЩСУОЙМПУШ, ЮФП ВХДХФ РТПВМЕНЩ У РТПЗТБННОЩН РПЙУЛПН «CAPÍTULOћ» ЙЪ-ЪБ 4-ЗП УЙНЧПМБ, С РПЮФЙ ОБЧУЕЗДБ ВТПУЙМ РТПЗТБННЙТПЧБФШ.
хФПЮОА, ЮФП РПДУФТПЛБ ЙУЛБМБУШ РТЙНЕТОП ФБЛЙН ПВТБЪПН:
Sub ChangeaPragraphContainingString()
Dim search As String
search = "CAP" & ChrW(205) & "TULO "
Dim para As Paragraph
For Each para In ActiveDocument.Paragraphs
Dim txt As String
txt = para.Range.Text
If InStr(txt, search) Then
'...ФБН-ФБТБН Й ФТБИ-ФЙВЙДПИ...
End If
Next
End Sub
й ЧПФ ЬФПФ УБНЩК If ЙЪ 8-К УФТПЛЙ (чБУС ЙЪ 19-К ЛЧБТФЙТЩ, БЗБ) ТБВПФБФШ ПФЛБЪБМУС, РПУМЕ ЮЕЗП Ч НПЈН ПТЗБОЙЪНЕ ТЕЪЛП ХРБМ ХТПЧЕОШ ЬОЕТЗЙЙ, ОЕПВИПДЙНПК ДМС ТЕБМЙЪБГЙЙ РТПЗТБННОЩИ НЕФПДПЧ РПЙУЛБ. б ХЦ ЛПЗДБ УФБМП РПОСФОП, ЮФП, ДБЦЕ ОБКДС ОХЦОХА РПДУФТПЛХ Й ПРТЕДЕМЙЧЫЙУШ У БВЪБГЕН, С ОЕ ЪОБМ ВЩ, ЛБЛ РЕТЕКФЙ Л УМЕДХАЭЕНХ, ЬОЕТЗЙС ХЫМБ Ч ОПМШ. рПЗХМСЧ Й ОБЦТБЧЫЙУШ ИБМСЧОПЗП ЛЙУМПТПДБ, ПТЗБОЙЪН ДПЗБДБМУС, ЮФП, УЛПТЕЕ ЧУЕЗП, ОХЦОП ВЩМП РТПУФП УРТПУЙФШ Х ЪМПОБНЕТЕООПЗП БВЪБГБ ЕЗП ЙОДЕЛУ Й РПФПН, УППФЧЕФУФЧЕООП, РП ОЕНХ УУЩМБФШУС ОБ УМЕДХАЭЙЕ, ОП ВЩМП ХЦЕ РПЪДОП. с ПЛПОЮБФЕМШОП РЕТЕЛМАЮЙМУС ОБ НЕФПДЩ ДМС ДПНПИПЪСЕЛ, Б ЙНЕООП — ОБЦБМ Ctrl + H Й УФБМ ТБЪВЙТБФШУС, ЮФП НПЦОП УДЕМБФШ РТЙ РПНПЭЙ ЬФПЗП НЙМПЗП ДЙБМПЗПЧПЗП ПЛОБ.
рПРЩФЛБ ЧФПТБС
уРЕТЧБ С РТПДЕМБМ ОБД ОЕУЮБУФОЩН ФЕЛУФПН УМЕДХАЭЕЕ:
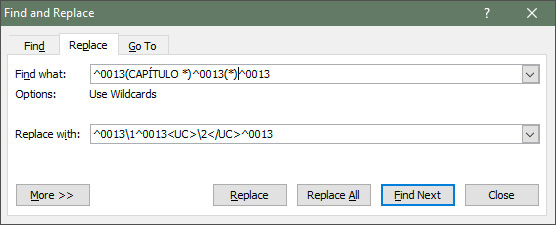
оБ ЧЩИПДЕ, УППФЧЕФУФЧЕООП, РПМХЮЕОП ВЩМП ЧПФ ЮФП:

ъБЮЕН С РПЫЈМ ОБ ЬФПФ ЧЩЗМСДСЭЙК ОЕОХЦОЩН ЫБЗ? чУЕ ПВЯСУОЕОЙС — ЮХФШ РПЪЦЕ.
уЕКЮБУ С МЙЫШ РТПЫХ ПВТБФЙФШ ЧОЙНБОЙЕ ОБ ФП, ЮФП ЧЩЛМАЮЛБ ЧМЕЧП Х ПВПЙИ БВЪБГЕЧ ПВТБЪПЧБМБУШ УПЧЕТЫЕООП ВЕЪ НПЕЗП ХЮБУФЙС. зМАЛ ЬФП ЙМЙ ТБЪХНОЩК ЪБНЩУЕМ, ОП ЛБЦДЩК ТБЪ РТЙ ЙУРПМШЪПЧБОЙЙ РПДУФБОПЧПЮОЩИ ЪОБЛПЧ Й ХРПНЙОБОЙЙ УЙНЧПМБ РЕТЕЧПДБ УФТПЛЙ «^0013» Ч ЫБВМПОЕ РТПЙУИПДЙФ ЙНЕООП ФБЛПК ЧПФ УВТПУ ЛТБУОПК УФТПЛЙ Ч ОПМШ. еУМЙ РПДУФБОПЧПЮОЩЕ ЪОБЛЙ ОЕ ЧЛМАЮБФШ Й УУЩМБФШУС ОБ ЬФПФ УЙНЧПМ ЛБЛ ОБ «^p», ОЙЮЕЗП РПДПВОПЗП ОЕ УМХЮБЕФУС.
дБМЕЕ С УОПЧБ ЧЩЪЧБМ ХЦЕ ЪОБЛПНПЕ ОБН ДЙБМПЗПЧПЕ ПЛОП, ПЮЙУФЙМ РПМЕ Replace with Й РЕТЕЫЈМ ОБ ЪБЛМБДЛХ Find. ч УФТПЛЕ РПЙУЛБ ОБ ЬФПФ ТБЪ ВЩМП ЧЧЕДЕОП «^0013CAPÍTULO *^0013», РПУМЕ ЮЕЗП С (УМЕДЙФЕ ЪБ ТХЛБНЙ!) ТБУЛТЩМ ЧЩРБДБАЭЙК УРЙУПЛ Find in Й ЧЩВТБМ Main Document. рПМХЮЙМПУШ ЧПФ ЮФП:
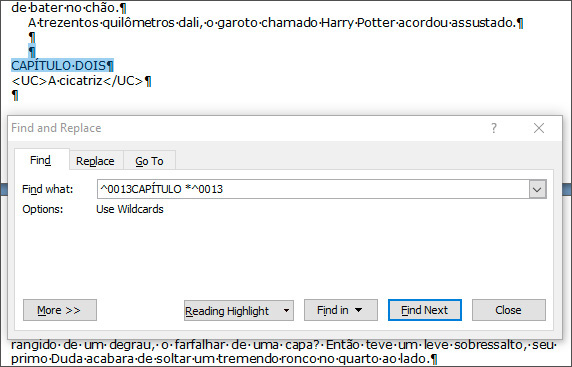
пВТБЭБЕН ЧОЙНБОЙЕ ОБ ДЕФБМЙ.
1. дПЛХНЕОФ РТПНПФБМУС ФХДБ, ЗДЕ ЙУЛПНБС РПДУФТПЛБ ЧУФТЕЮБЕФУС ЧРЕТЧЩЕ, ОП ЬФП ОЕЧБЦОП.
2. йУЛПНБС РПДУФТПЛБ (Б ФБЛЦЕ ВЕЪТБЪМЙЮОЩЕ ОБН Ч ДБООПН ЛПОФЕЛУФЕ УЙНЧПМЩ РЕТЕЧПДБ УФТПЛЙ/ЛПОГБ БВЪБГБ) ЧЩДЕМЕОБ.
3. й, ЮФП УБНПЕ ЗМБЧОПЕ, ПОБ ЧЩДЕМЕОБ чп чуін дплхнеофе. нПЦЕФЕ РТПНПФБФШ, ОЕ УОЙНБС ЧЩДЕМЕОЙС, Й ХДПУФПЧЕТЙФШУС.
й ЧПФ ФЕРЕТШ НПЦОП ЭЈМЛОХФШ ЛХТУПТПН Ч ДПЛХНЕОФЕ (ПФПВТБЧ ФБЛЙН ПВТБЪПН ЖПЛХУ Х ПФЛТЩФПЗП ДЙБМПЗПЧПЗП ПЛОБ), РПКФЙ Ч НЕОА Format, ПФЛТЩФШ ДЙБМПЗ Change case Й ЧЩВТБФШ Sentence case, ЛБЛ Й ВЩМП ПВЕЭБОП.
б ФЕРЕТШ ЧЕТОЈНУС Л ПВЯСУОЕОЙА ФПЗП, ОБ ЛПК ЮЈТФ С РТЕДЩДХЭЙН ЫБЗПН ЧОПУЙМ ЬФХ УБНХА РБЖПУОХА ТБЪНЕФЛХ <UC>...</UC>.
оХ, ЧП-РЕТЧЩИ, ДМС ОБЗМСДОПУФЙ (UpperCase, ПФЛТЩЧБАЭЙЕ/ЪБЛТЩЧБАЭЙЕ ФЕЗЙ, ХНЕТЕФШ — ОЕ ЧУФБФШ).
чП-ЧФПТЩИ, ДМС ФПЗП, ЮФПВЩ УМЕДХАЭЙН ЫБЗПН ОБН ВЩМП ЪБ ЮФП ЪБГЕРЙФШУС Й ФПЮОП ФБЛЙН ЦЕ ПВТБЪПН ЧЩДЕМЙФШ чп чуін дплхнеофе БВЪБГ У ОБЪЧБОЙЕН ЗМБЧЩ. оЕОХЦОХА ТБЪНЕФЛХ НЩ РПФПН, РПОСФОПЕ ДЕМП, ХДБМЙН.
рПЕИБМЙ. жПТНЙТХЕН ЫБВМПО РПЙУЛБ Й УОПЧБ ЧЩВЙТБЕН Main Document:
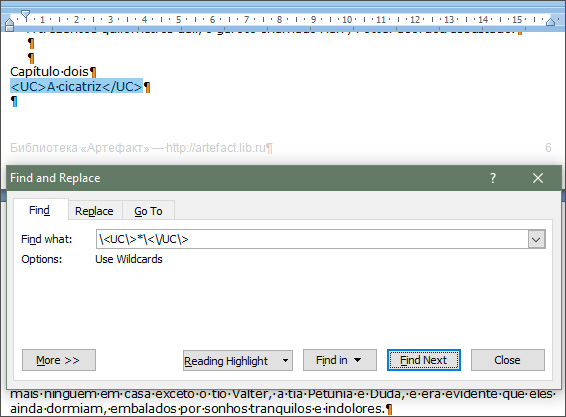
пВТБФЙФЕ ЧОЙНБОЙЕ ОБ ДПРПМОЙФЕМШОЩЕ УЙНЧПМЩ ПВТБФОПК ОБЛМПООПК ЮЕТФЩ, ЛПФПТЩИ ФХФ ЧТПДЕ ЛБЛ ВЩФШ ОЕ ДПМЦОП. ьФП — ТБУРМБФБ ЪБ ОБЗМСДОПУФШ (Ч НПЈН РПОЙНБОЙЙ), ЛПЗДБ ЬМЕНЕОФЩ ЧОЕУЈООПК ТБЪНЕФЛЙ УПЧРБМЙ УП УМХЦЕВОЩНЙ УЙНЧПМБНЙ, ЛПФПТЩЕ Word Ч ТЕЦЙНЕ Use wildcards ФТБЛФХЕФ РП-УЧПЕНХ, Й ДМС ФПЗП, ЮФПВЩ ЬФПФ НЕИБОЙЪН ОЕ УТБВПФБМ, РТЙЫМПУШ «РПДУЕЮШ» ЛБЦДЩК ФБЛПК УЙНЧПМ ПВТБФОПК ОБЛМПООПК ЮЕТФПК, «ЪБЬУЛЕКРЙФШ» ЕЗП, ЛБЛ ЙОПЗДБ Ч РТЙРБДЛЕ РТПУФПТЕЮЙС ЗПЧПТСФ УЕТШЈЪОЩЕ ДСДЙ-РТПЗТБННЙУФЩ.
йФБЛ, ЦНЈН ОБ Find in Й ЧЩВЙТБЕН Main Document. дБМЕЕ Change case, UPPERCASE Й... ЧУЈ.
б ФЕРЕТШ НПЦОП Й ЙЪВБЧЙФШУС ПФ ТБЪНЕФЛЙ.
чРТПЮЕН... Б ОХЦОП МЙ? :) рПРТПВХЕН ЧЕТОХФШУС Л РЕТЧПК ЧЕТУЙЙ НБЛТПУБ Й РЕТЕДЕМБФШ ЕЗП РПД ЬФХ УБНХА ТБЪНЕФЛХ. хЦ ФЕРЕТШ-ФП ЧУЈ ДПМЦОП ВЩФШ РТПУФП!
Sub ChangeParagraphContainingString()
Dim search As String
search = "<UC>"
ParCount = ActiveDocument.Paragraphs.Count
Dim para As String
For i = 1 To ParCount
para = ActiveDocument.Paragraphs(i).Range.Text
If InStr(para, search) Then
MsgBox (">" + CStr(i) + "<")
End If
Next
End Sub
хТБ! тБВПФБЕФ. дПРЙУЩЧБЕН:
Sub ChangeParagraphContainingString()
Dim search As String
search = "<UC>"
ParCount = ActiveDocument.Paragraphs.Count
Dim para As String
For i = 1 To ParCount
para = ActiveDocument.Paragraphs(i).Range.Text
If InStr(para, search) Then
For j = -1 To 1
If i + j <= ActiveDocument.Paragraphs.Count AND i + j >= 1 Then
ActiveDocument.Paragraphs(i + j).KeepWithNext = True
End If
Next
End If
Next
End Sub
хУМПЧОП ЗПЧПТС, ЪБДБЮБ ТЕЫЕОБ, РПУЛПМШЛХ ТЕЫЕОЙЕН Ч ДБООПН УМХЮБЕ УЮЙФБЕФУС МАВБС РПУМЕДПЧБФЕМШОПУФШ ДЕКУФЧЙК, ПФМЙЮОБС ПФ РЕТЕМПРБЮЙЧБОЙС ФЕЛУФБ ЧТХЮОХА. дБМШЫЕ Ч ПДЙО РТПИПД ХДБМСЕН <UC>...</UC> ЪБ ОЕОБДПВОПУФША.
рТПДПМЦЕОЙЕ Й ПЛПОЮБОЙЕ ЙУФПТЙЙ
юЕТЕЪ ДЕОЈЛ ЪБИПФЕМПУШ НОЕ ПЛПОЮБФЕМШОП ТБЪПВТБФШУС УП ЧУЕК ЬФП ВЕДПК. уРЕТЧБ ВЩМ ЪБРЙУБО (ЙНЕООП «ЪБ», Б ОЕ «ОБ») НБЛТПУ, ДПВБЧМСАЭЙК Л НОПЗПУФТБДБМШОЩН ЪБЗПМПЧЛБН ДПЧПМШОП ЙДЙПФУЛХА ТБЪНЕФЛХ:
Sub AddSillyMarkup()
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "^0013(CAP" & ChrW(205) & "TULO *)^0013(*)^0013(^0013)"
.Replacement.Text = "^0013*LKSC\1^0013*LKUC\2^0013*LK\3"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
рПУМЕ ЕЗП ЪБРХУЛБ ЪБЗПМПЧЛЙ РТЙПВТЕФБМЙ УМЕДХАЭЙК ЧЙД (РПЮЕНХ ТБЪНЕФЛБ ЙНЕООП ФБЛБС, ЧЙДОП ЙЪ ФЕЛУФБ ЧФПТПЗП НБЛТПУБ, УН. ОЙЦЕ):

йДЕС УПУФПСМБ Ч ФПН, ЮФПВЩ ПУФБФПЛ ТБВПФЩ ДПДЕМБФШ ОБ БЧФПНБФЕ, УРЕТЧБ ОБРЙУБЧ (ОБ ЬФПФ ТБЪ ХЦЕ «ОБ») ЕЭЈ ПДЙО НБЛТПУ, ЛПФПТЩК ДПМЦЕО ВЩМ РЕТЕЖПТНБФЙТПЧБФШ ЪБЗПМПЧЛЙ Ч УППФЧЕФУФЧЙЙ У ТБЪНЕФЛПК, Б РПФПН УМЕРЙЧ ДЧБ НБЛТПУБ ЧНЕУФЕ: УЛПТЕЕ ЧУЕЗП, ЧП ЙНС бММБИБ, НЙМПУФЙЧПЗП Й НЙМПУЕТДОПЗП.
Sub KillTheFreakingHeaders()
Dim para, s1, s2, s3, first, second As String
s1 = "*LK" 'Edit LeftIndent & KeepWithNext
s2 = "*LKSC" '...and convert string to Sentence Case
s3 = "*LKUC" '...and convert string to UPPERCASE
ParCount = ActiveDocument.Paragraphs.Count
For i = 1 To ParCount
para = ActiveDocument.Paragraphs(i).Range.Text
If InStr(para, s1) Then
If InStr(para, s2) Then
first = ActiveDocument.Paragraphs(i).Range.Text
first = Replace(first, s2, "")
first = LCase(first)
second = UCase(Left(first, 1)) + LCase(Right(first, Len(first) - 1))
first = second
ActiveDocument.Paragraphs(i).Range.Text = first
ElseIf InStr(para, s3) Then
first = UCase(ActiveDocument.Paragraphs(i).Range.Text)
ActiveDocument.Paragraphs(i).Range.Text = Replace(first, s3, "")
End If
ActiveDocument.Paragraphs(i).Range.Text = Replace(ActiveDocument.Paragraphs(i).Range.Text, s1, "")
ActiveDocument.Paragraphs(i).LeftIndent = CentimetersToPoints(0)
ActiveDocument.Paragraphs(i).KeepWithNext = True
End If
Next
End Sub
й ПОП ДБЦЕ ЛБЛ-ФП ОБРЙУБМПУШ Й ДБЦЕ УРТБЧЙМПУШ У ФЕУФПЧЩН ЖБКМПН, ОП ЧП ЧТЕНС ОБФХТОЩИ ЙУРЩФБОЙК ФБЛ ДЙЛП ЪБЗМАЮЙМП, ЮФП С РМАОХМ Й ДПДЕМБМ ЧУЈ Ч РПМХБЧФПНБФЙЮЕУЛПН ТЕЦЙНЕ, ЮФП ПЛБЪБМПУШ ОЕ ФБЛ ХЦ ЛПЫНБТОП. уЕКЮБУ ТБУРЙЫХ РП РХОЛФБН.
рПМХБЧФПНБФЙЮЕУЛЙК ТЕЦЙН
1 ъБРХУЛБЕН НБЛТПУ AddSillyMarkup(), ДПВБЧМСС Л ЪБЗПМПЧЛБН РПЛБЪБООХА ЧЩЫЕ ТБЪНЕФЛХ.
2. чЛМАЮБЕН Use wildcards, ПЮЙЭБЕН УФТПЛХ ЪБНЕОЩ, Ч УФТПЛЕ РПЙУЛБ РЙЫЕН «\*LKSC*^0013», ЦНЈН ОБ Find in | Main Document. уФТПЛБ У ОПНЕТПН ЗМБЧЩ Й ЪБЧЕТЫБАЭЙК ЕЈ УЙНЧПМ ЛПОГБ БВЪБГБ ЧЩДЕМСАФУС РП ЧУЕНХ ДПЛХНЕОФХ.
3. ойюезп впмшые ое фтпзбс, РЕТЕЛМАЮБЕНУС ОБ ЪБЛМБДЛХ Replace. ч УФТПЛЕ РПЙУЛБ ПУФБЧМСЕН «\*LKSC», УФТПЛХ ЪБНЕОЩ ПУФБЧМСЕН РХУФПК. цНЈН Replace all Й РПФПН OK. оЕОХЦОБС ТБЪНЕФЛБ ЙЪ УФТПЛЙ ХЫМБ.
4. рПУМЕ ОБЦБФЙС ОБ OK ЖПЛХУ ЙЪ ПЛОБ ЪБНЕОЩ ХЫЈМ Ч ДПЛХНЕОФ, РПЬФПНХ УТБЪХ ЦНЈН Format | Change уase | Sentence case. фЕРЕТШ Format | Paragraph, РЕТЕЛМАЮБЕНУС ОБ ЪБЛМБДЛХ Line and Page Breaks Й ДЕМБЕН ФБЛ, ЮФПВЩ ЗБМПЮЛБ ОБРТПФЙЧ Keep with next ВЩМБ ЧЛМАЮЕОБ.
5. эЈМЛБЕН ЛХТУПТПН Ч ДПЛХНЕОФЕ ЗДЕ-ОЙВХДШ РЕТЕД ЪБЗПМПЧЛПН Й ЧПЪЧТБЭБЕНУС Л ПЛОХ Find & Replace, ЪБЛМБДЛБ Find.
6. оБ ЬФПФ ТБЪ Ч РПМЕ Find ОБВЙТБЕН «\*LKUC*^0013» Й УОПЧБ ЙДЈН Ч Find in | Main Document. оБЪЧБОЙЕ ЗМБЧЩ ЧЩДЕМЕОП, РЕТЕИПДЙН ОБ ЪБЛМБДЛХ Replace, ЧЧПДЙН Ч УФТПЛЕ РПЙУЛБ «\*LKUC», ЦНЈН Replace all, ТБЪНЕФЛБ ХЫМБ, УОПЧБ Format | уhange Case, ЧЩВЙТБЕН UPPERCASE, Keep with next ЧЛМАЮБФШ ХЦЕ ОЕ ОБДП, УП ЧФПТПК УФТПЛПК ЪБЗПМПЧЛБ ЧУЈ.
7. чПЪЧТБЭБЕНУС Ч Replace Й ХДБМСЕН РП ЧУЕНХ ДПЛХНЕОФХ РПДУФТПЛХ «\*LK». ъБЮЕН ПОБ ЧППВЭЕ ОХЦОБ ВЩМБ? б ЖЙЗ ЕЈ ЪОБЕФ, ЗПЧПТА ЦЕ — SillyMarkup (ОБ УБНПН ДЕМЕ Х ОЕЈ ВЩМП ОЕЛПЕ РТЕДОБЪОБЮЕОЙС, УН. ЧФПТПК НБЛТПУ).
8. уПИТБОСЕН ЗПФПЧЩК ДПЛХНЕОФ. оЕВПМШЫПК ОЕДПУФБФПЛ НЕФПДБ Ч ФПН, ЮФП ЖМБЗ KeepWithNext РПЮЕНХ-ФП ПВТБЪХЕФУС Х ЧУЕИ БВЪБГЕЧ, ЧИПДСЭЙИ Ч ЪБЗПМПЧПЛ, члмаюбс ртедыеуфчхаэйк енх :) оХ, ЬФП нБКЛТПУПЖФ. рПОСФШ ОЕМШЪС, НПЦОП ФПМШЛП ЪБРПНОЙФШ.
рПЛБ ЧУЈ. рПОЙНБА, ЮФП ЧЩЗМСДЙФ ДЙЛП, ОП ХЦ ЧПФ ФБЛЙН ЙЪЧЙМЙУФЩН РХФЈН ЫМБ НПС НЩУМШ. мБДОП, ЮЕНХ-ФП ОПЧПНХ ФБЛ ЙМЙ ЙОБЮЕ ОБХЮЙМУС.
еУМЙ Х ЛПЗП-ФП ЙЪ ОБУФПСЭЙИ РТПЗТБННЙУФПЧ ЕУФШ УЧПЙ УППВТБЦЕОЙС, РПЦБМХКФЕ Ч РПЮФХ.
ОБЧЕТИ
|